AnW Übung 12 Read-Up
Kontakt
E-Mail: toffermann@ethz.ch
Website/ Unterlagen: https://n.ethz.ch/~toffermann/
Plan für heute
- Minitest
- Theorie Recap
- In-Class Exercise
Themen der Vorlesung
- MIN-CUT Problem
Multi-Graph gegeben (ungerichtet, ungewichtet, ohne Schleifen)
Wir fragen uns wie viele Kanten müssen entfernt werden, so dass nicht mehr zusammenhängend ist.
Mit bezeichnen wir die kleinste Anzahl an zu entfernenden Kanten:
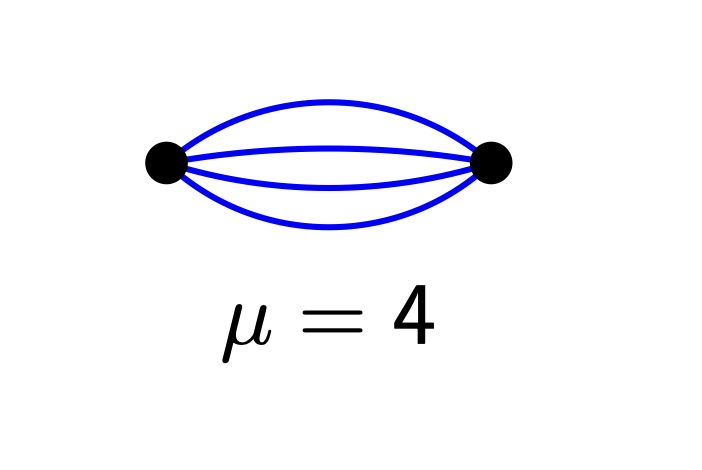
Anzahl anliegende Kanten
Es gilt:
- Handschlag-Lemma:
-
- Deterministisch mit Flüssen
Wir wissen, wie man den kleinsten --Schnitt berechnet (maximaler Fluss von nach ). Dieser gibt an wie viele Kanten, bzw. wie viel Kantengewicht man minimal entfernen muss, um von zu trennen.
Für unseren Multigraphen können wir unser Netzwerk folgendermaßen bilden:
Nehmen wir Multigraph:Wir können diese ungewichteten Kanten in unserem Netzwerk als eine Kante mit Gewicht darstellen. Weil die Kante ungerichtet ist müssen wir in dem Netzwerk zwei Kanten mit Gewicht für beide Richtungen einfügen.
Ist die Kante mit Gewicht dann Teil des minimalen Schnittes, so müssen in unserem ursprünglichen Multigraphen ebenso alle Kanten entfernt werden um den Zusammenhang zu zerstören.
Betrachten wir eine optimale MIN-CUT Lösung mit . Nehmen wir an besteht dann aus zwei Zusammenhangskomponenten .
Wenn wir nur einen --Schnitt für unsere Lösung betrachten könnte es sein, dass sowohl , als auch in der selben Zusammenhangskomponente liegen. Wenn wir dann den minimalen --Schnitt berechnen kann es sein, dass wir nicht mehr die beste Lösung finden.
Dementsprechend müssen wir für ein fixes einmal alle Knoten als unser durchprobieren.
Laufzeit ein Durchlauf: (Dynamic Trees)
Wir probieren alle Knoten als unser aus. Ergibt Laufzeit , wegen
- Erster randomisierte Ansatz
Der Algorithmus basiert auf Kantenkontraktion.
Kontrahieren wir eine Kante so werden zu einem neuen Knoten , der weiterhin mit allen Nachbarn von , sowie verbunden ist. Es gehen alle Kanten zwischen verloren:

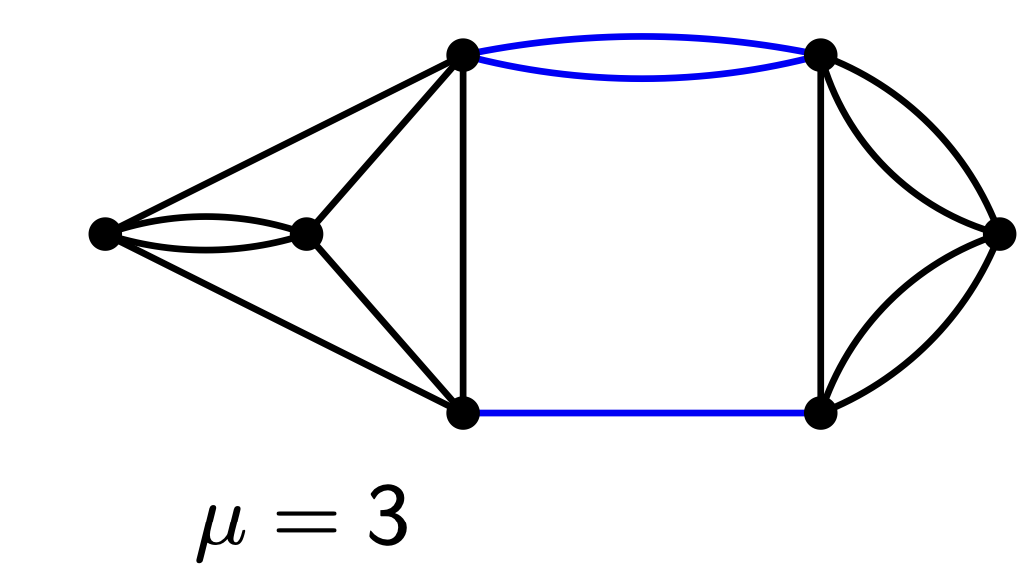
Im folgenden Graphen sind die blauen Kanten :
Kontrahieren wir Kanten die nicht blau sind , so gilt . Haben wir also “Glück” und ziehen immer Kanten die nicht blau sind, und kontrahieren diese, so finden wir am Ende zwei Knoten zwischen denen die blauen Kanten liegen. Die Anzahl dieser Kanten gibt an.
Wenn wir aus versehen eine blaue Kante ziehen und kontrahieren, dann kann es sein, dass der minimale Schnitt in größer ist als der in .
Wir fassen zusammen:
-
-
(Beachte, dass das Beispiel mit den blauen Kanten nicht komplett richtig ist. Es gibt möglicher Weise mehrere minimale Schnitte und nicht nur einen. Die Aussagen sind immer so gemeint, dass wenn wir ziehen, es weiterhin einen minimalen Schnitt in ohne gibt. Diese Kanten wären dann die “nicht blauen” Kanten)
Wir leiten daraus folgenden Algorithmus ab:

Wie oben beschrieben kann CUT() mit einer Wahrscheinlichkeit die richtige Antwort liefern (Wenn wir immer nicht-blaue Kanten wählen). Was ist aber ?
Wir nehmen an, dass für einen gegebenen minimalen Schnitt und betrachten :
- , weil somit definitiv “nicht-blau” ist (gibt es noch einen anderen minimalen Schnitt so könnte es sein, dass wir wählen dürfen und damit beibehalten, daher ist oben ein “” und kein “”)
- ,
und
- Also insgesamt:
gibt an wie wahrscheinlich es ist, dass wir im ersten Schritt von CUT() keinen Fehler machen ( gibt nur die Anzahl der Knoten vor der Kontraktion an).
Damit können wir eine untere Schranke für geben:
Wir wiederholen den Algorithmus mal. Die Wahrscheinlichkeit, dass immer eine falsche Antwort gegeben wird ist . Angewandte Ungleichung:
Also gibt es eine richtige Antwort mit Wahrscheinlichkeit . Für haben wir Laufzeit und Fehler .
- Laufzeit ein Durchlauf CUT() ist
- viele Durchläufe
- Also insgesamt
- Bei Knoten Abbrechen
Wir beobachten, dass der Algorithmus in den letzten Schritten die meisten Fehler macht:
Daher stoppen wir den Algorithmus wenn wir noch Knoten übrig haben (welches das Beste ist bestimmen wir gleich) und rechnen danach mit einem bekannten Algorithmus weiter.
Den Algorithmus den wir in den letzen Runden verwenden ist der randomisierte Algorithmus von oben mit
- Laufzeit
- Richtig mit Wahrscheinlichkeit
Wenn wir diesen Algorithmus nun mal laufen lassen erhalten wir wieder ein richtiges Ergebnis mit Wahrscheinlichkeit .
Laufzeit:
- Ein Durchlauf kontrahiert Knoten in Zeit und rechnet danach in Zeit den Rest zu Ende insgesamt abgeschätzt
- Wir haben Wiederholungen
- Multiplikation ergibt finale Laufzeit:
- Für hat man Laufzeit:
- Bootstrapping
Im obigen Schritt haben wir den Algorithmus “abgebrochen”, wenn es noch Knoten gab und ab da mit einem bekannten Algorithmus weiter gerechnet.
Dafür haben wir unseren ersten randomisierten CUT()-Algo mit verwendet. Dieser hatte Laufzeit .
Gerade haben wir aber einen Algorithmus kreiert der für mit der selben Erfolgswahrscheinlichkeit (selben lower-bound) in statt läuft. Deswegen können wir das gleiche Verfahren nochmals mit dem statt Algorithmus starten und bekommen für ein neues dann einen noch schnelleren Algorithmus den wir wieder anstelle des Algorithmus einsetzen können.
Im Grenzwert erhält man dann einen Algorithmus.