Chapter 3 Planning for precision and power
In our example, we found that twenty mice were insufficient to conclude if the two kits provide comparable measurements on average or not. We now discuss sample size determination, techniques to determine the necessary sample size for a desired precision of the difference estimate \(\hat{\Delta}=\hat{\mu}_A-\hat{\mu}_B\), and power analysis, which does the same to achieve a desired power for testing \(H_0:\Delta=0\) using the corresponding \(t\)-test.
Both confidence interval and test statistic depend on the true effect size \(\Delta\) and on the size of the standard error of its estimate. Since \(\Delta\) is usually not under the control of the experimenter, we concentrate on methods to reduce the standard error \(\text{se}(\hat{\Delta})=2\sigma/\sqrt{n}\): (i) balanced and unbalanced allocation of a fixed number of samples to the treatment groups; (ii) reducing the standard deviation \(\sigma\) of the responses; and (iii) increasing the sample size \(n\).
3.1 Balancing allocation
Without comment, we always used a balanced allocation, where the same number of experimental units is allocated to each treatment group. This choice seems intuitively sensible, and we quickly confirm that this intuition indeed yields the highest precision and power in our example. We will later also see that in more complex designs, unbalanced allocation not only decreases precision, but might prevent estimation of relevant treatment effects altogether.
We denote by \(n_A\) and \(n_B\) the number of mice allocated to kit A and B, respectively, and estimate the two expectations by \(\hat{\mu}_A=\sum_{i=1}^{n_A}y_{i,A}/n_A\) and correspondingly for \(\hat{\mu}_B\). The standard error of our estimate is then \[ \text{se}(\hat{\mu}_A-\hat{\mu}_B) = \sqrt{\frac{1}{n_A}+\frac{1}{n_B}}\cdot\sigma\;. \] For fixed total sample size \(n_A+n_B\), this standard error is minimal for a balanced allocation with treatment groups of equal size \(n_A=n_B\), provided the variation \(\sigma\) is identical in both treatment groups. The more unbalanced the allocation is, the larger the standard error will become.
To illustrate, we consider two experimental designs with a total sample size of \(n_A+n_B=20\): first, we assign a single mouse to vendor B (\(n_B=1\)), and the remaining 19 mice to vendor A (\(n_A=19\)). Then, \[ \text{se}_{19,1} = \sqrt{\frac{1}{19}+\frac{1}{1}}\cdot\sigma = 1.026\,\sigma \] and the standard error is even higher than the dispersion in the population! However, if we assign the mice equally (\(n_A=n_B=10\)), we get a substantially lower standard error of \[ \text{se}_{10,10} = \sqrt{\frac{1}{10}+\frac{1}{10}}\cdot\sigma = 0.45\,\sigma\;. \]
The relative efficiency of the two designs \[ \text{RE} = \frac{\text{se}_{19,1}^2}{\text{se}_{10,10}^2} = \left(\frac{1.026}{0.45}\right)^2 \approx 5.2\;. \] allows us to directly compare the precision of the two allocation strategies. It is the increase in sample size needed for the first experiment to match the precision of the second. Here, the unbalanced allocation would require more than five times more mice to match the precision of the balanced design. This would mean using at least 5 mice for vendor B and 95 mice for vendor A (100 mice in total). Dividing the experimental material inaptly results in substantial loss of precision, which is very costly to make up for.
If the two treatment groups have very different standard deviations \(\sigma_A\) and \(\sigma_B\), then an unbalanced allocation is advantageous, where more experimental units are allocated to the more variable treatment group. The standard error is \[ \text{se}(\hat{\mu}_A-\hat{\mu}_B) = \sqrt{\frac{\sigma_A^2}{n_A}+\frac{\sigma_B^2}{n_B}}\;. \]
For a total sample size of \(n_A+n_B=20\) mice and \(\sigma_A=2.8\) twice as large as \(\sigma_B=1.4\), we should allocate \(n_A=\) 13 and \(n_B=\) 7 mice, respectively. This ratio changes to \(n_A=\) 16 and \(n_B=\) 4 mice if we increase the standard deviation in group A to \(\sigma_A=5.6\). Very disparate standard errors in the different treatment groups are often a sign that the treatment groups are different in ways other than the assigned treatment alone; such a situation will require more care in the statistical analysis.
3.2 Reducing the standard error
We can increase precision and power by reducing the standard deviation \(\sigma\) of our response values. This option is very attractive, since reducing \(\sigma\) to one-half will also cut the standard error to one-half, and increase the value of the \(t\)-statistic by two, without altering the necessary sample size.
Recall that the standard deviation describes how dispersed the measured enzyme levels of individual mice are around the population mean in each treatment group. This dispersion contains the biological variation \(\sigma_m\) from mouse to mouse, and the variation \(\sigma_e\) due to within-mouse variability and measurement error, such that \[ \sigma^2=\sigma_m^2+\sigma_e^2 \quad\text{and}\quad \text{se}(\hat{\Delta}) = \sqrt{2\cdot\left( \frac{\sigma_m^2+\sigma_e^2}{n}\right)} \;. \]
3.2.1 Subsampling
If the variance \(\sigma2\) is dominated by variation between samples of the same mouse, we can reduce the standard error by taking multiple samples from each mouse and averaging their measured enzyme levels to compute the mouse’s response. Since the number of experimental units does not change, the measurements from the samples are sometimes called technical replicates as opposed to biological replicates. If we take \(m\) samples per mouse, this reduces the variance of these new responses to \(\sigma_m^2+\sigma_e^2/m\), and the standard error to \[ \text{se}(\hat{\Delta}) = \sqrt{ 2\cdot \left(\frac{\sigma_m^2}{n}+\frac{\sigma_e^2}{m\cdot n}\right)}\;. \] We can employ the same strategy if the measurement error is sufficiently large, and we decrease its influence on the standard error by taking \(r\) measurements of each of \(m\) samples.
This strategy is called sub-sampling because we use the average of multiple recorded responses for each experimental unit. It is only successful in increasing precision and power substantially if \(\sigma_e\) is not small compared to the between-mouse variation \(\sigma_m\), since the contribution of \(\sigma_m\) on the standard error only depends on the number \(n\) of mice, and not on the number \(m\) of samples per mouse. In biological experiments, the biological (mouse-to-mouse) variation is typically much larger than the technical (sample-to-sample) variation and sub-sampling is often of very limited use. Indeed, a very common mistake is to ignore the difference between technical and biological replicates and treat all measurements as biological replicates. This flaw is known as pseudo-replication and leads to (massively) overestimating the precision of an estimate and thus to much shorter, incorrect, confidence intervals, and to overestimating the power of a test, with too low \(p\)-values and high probability of false positives (Hurlbert 1984,@hurlbert2009a).
For our example, the between-mouse variance is \(\sigma_m^2=\) 1.9 and much larger than the within-mouse variance \(\sigma_e^2=\) 0.1. For ten mice per treatment group and one sample per mouse, the standard error is 0.89. Increasing the number of samples to \(m=2\) reduces this error to 0.88 and even increasing this number to an unrealistic \(m=100\) only reduces the error down to 0.87. In contrast, using 11 instead of 10 mice per treatment reduces the standard error already to 0.85.
3.2.2 Narrowing the experimental conditions
We can reduce the standard deviation \(\sigma\) of the observations by tightly controlling experimental conditions, for example by keeping temperatures and other environmental factors at a specific level, reducing the diversity of the experimental material and similar measures. These measures reduce the variation in the experimental material or responses and make estimates and comparisons more precise.
For our example, we can reduce the between-mouse variation \(\sigma_m\) by restricting attention to a narrower population of mice. If we sample only female mice within a narrow age span from a particular laboratory strand, the variation might be substantially lower than for a broader selection of mice.
However, by ever more tightly controlling the experimental conditions, we simultaneously restrict the generalizability of the findings to the more narrow conditions of the experiment. Claiming that the results should also hold for a wider population (i.e., other age cohorts, male mice, more than one laboratory strand) requires external arguments and cannot be supported by the data from our experiment.
3.2.3 Blocking
Looking at our experimental question more carefully, we discover a simple yet highly efficient technique to completely remove the largest contributor \(\sigma_m\) from the standard error. The key observation is that we apply each kit to a sample from a mouse and not to the mouse directly. Rather than taking one sample per mouse and randomly allocating it to either kit, we can also take two samples from each mouse, and randomly assign kit A to one sample, and kit B to the other sample. For each mouse, we estimate the difference between vendors by subtracting the two measurements, and average these differences over the mice. Each individual difference is measured under very tight experimental conditions (within a single mouse); provided the differences vary randomly and independently of the mouse (note that the measurements themselves of course depend on the mouse!), their average yields a within-mouse estimate \(\hat{\Delta}\).
Such an experimental design is called a blocked design, where the mice are blocks for the samples: they group the samples into pairs belonging to the same mouse, and the treatments are randomly allocated to the units independently within each block.
Following the arguments in Section 2.2.5.3, the standard error for \(n\) mice is then \[ \text{se}(\hat{\Delta}) = \sqrt{2\cdot\frac{\sigma_e^2}{n}}\;, \] and the number of mice for the experiment is reduced from \(2n\) to \(n\).
For our example with \(\sigma_m^2=\) 1.9 and \(\sigma_e^2=\) 0.1, this reduces the standard error from 0.89 for \(n=2\cdot 10\) mice in our original experiment to 0.2 for \(n=10\) mice in the new experiment. The relative efficiency between unblocked and blocked experiment is \(\text{RE}=\) 20, indicating that blocking allows a massive reduction in sample size while keeping the same precision and power.
| Mouse | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| A | 9.14 | 9.47 | 11.14 | 12.45 | 10.88 | 8.49 | 7.62 | 13.05 | 9.67 | 11.63 |
| B | 9.19 | 9.70 | 11.12 | 12.62 | 11.50 | 8.99 | 7.54 | 13.38 | 10.94 | 12.28 |
For the example data in Table 3.1, we estimate a difference between kits of \(\hat{\Delta}=\) -0.37 and a residual variance of \(\hat{\sigma}^2_e=\) 0.08. The 95%-confidence interval for \(\Delta\) is [-0.66, -0.08], much narrower than for the previous design where we calculated an interval of [-1.89, 1.21]. Note that this confidence interval is based on \(t\)-quantiles with \(n-1\) instead of the previous \(2n-2\) degrees of freedom. For the same standard error, these quantiles would yield a slightly wider confidence interval before, but this effect is more than compensated by the massive decrease of the standard error.
As expected, the \(t\)-test also profits from the reduced standard error. The \(t\)-statistic is now \(t=\) -2.9 leading to a \(p\)-value of \(p=\) 0.018 and thus a significant result at the 5%-significance level. This compares to the previous \(t\)-value of \(t=\) -0.65 for the unblocked design with a \(p\)-value of 0.52.
3.3 Sample size and precision
“How many samples do I need?” is arguably among the first questions a researcher poses when thinking about an experimental design. Sample size determination is a crucial component of experimental design in order to ensure that estimates are sufficiently precise to be of practical value and that hypothesis tests are adequately powered to be able to detect a relevant effect size. Sample size determination crucially depends on deciding on a minimal effect size. While precision and power can always be increased indefinitely by increasing the sample size, limits on resources—time, money, available experimental material—pose practical limits and there is also a diminishing return, as doubling precision requires quadrupling the sample size.
3.3.1 Sample size for desired precision
To provide a concrete example, let us consider our comparison of the two preparation kits again and assume that the volume of blood require is prohibitive for more than one sample per mouse. In the last experiment based on 20 mice, we found that our estimate \(\hat{\Delta}\) was too imprecise to determine with any confidence which—if any—of the two kits yields lower reponses than the other.
To determine a sufficient samples size, we need to decide which minimal effect size is relevant for us, a question answerable only with experience and subject-matter knowledge. For the sake of the example, let us say that a difference of \(\delta_0=\pm 0.5\) or larger would mean that we stick with one vendor, but a difference smaller is not of practical relevance for us. The task is therefore to determine the number of mice \(n\) per treatment group, such that the confidence interval of \(\Delta\) has width no more than one, i.e., that \[ \text{UCL}-\text{LCL} = (\hat{\Delta}+t_{1-\alpha/2,2n-2}\cdot\text{se}(\hat{\Delta}))-(\hat{\Delta}+t_{\alpha/2,2n-2}\cdot\text{se}(\hat{\Delta}))\leq 2|\delta_0|=1\;. \] We note that both the \(t\)-quantiles and the standard error depend on \(n\), which prevents us from solving this inequality directly. For a precise calculation, we can start at some not too large \(n\), calculate the width of the confidence interval, and increase \(n\) and repeat if the width is too large.
If we have reason to believe that \(n\) will not be very small, then we can exploit the fact that the \(t\)-quantile \(t_{\alpha,n}\) is approximately equal to the standard normal quantile \(z_\alpha\) for larger \(n\), and that \(z_\alpha\) does not depend on the sample size. This reduces the problem to \[ \text{UCL}-\text{LCL} = (z_{1-\alpha/2}-z_{\alpha/2})\sqrt{2}\sigma/\sqrt{n} \leq 1 \implies n\geq 2\cdot\left(2z_{1-\alpha/2}\sigma\right)^2\;. \] For a 95%-confidence interval, the standard normal quantiles are \(z_{0.025}=-1.96\) and \(z_{0.975}=+1.96\), which we can approximate as \(\pm 2\) without introducing any meaningful error. This leads to the simple formula \[ n \geq 2\cdot\left(2\cdot 2\sigma\right)^2 = 32\cdot\sigma^2\;. \]
In order to actually calculate the sample size with this formula, we need to know the standard deviation of the enzyme levels or an estimate \(\hat{\sigma}\). Such an estimate might be available from previous experiments on the same problem. If not, we have to conduct a separate (usually small) experiment using a single treatment group for getting such an estimate. In our case, we already have an estimate \(\hat{\sigma}=\) 1.65 from our previous experiment. Using this estimate, we find that a sample size of \(n=\) 84 mice per kit is required to reach our desired precision (the approximation \(z_{0.975}=2\) yields \(n=\) 87). This is a substantial increase in experimental material needed. We will have to decide if an experiment of this size is feasible for us, but a smaller experiment will likely waste time and resources without providing a practically relevant answer.
3.3.2 Precision for given sample size
It is often useful to turn the question around: given we can afford a certain maximal number of mice for our experiment, what precision can we expect? If this precision turns out to be insufficient for our needs, we might as well call the experiment off or start considering alternatives.
For example, let us assume that we have 40 mice at our disposal for the experiment. From our previous discussion, we know that the variances of measurements using kits A and B can be assumed equal, so a balanced assignment of \(n=20\) mice per vendor is optimal. The expected width of a 95%-confidence interval is \[ \text{UCL}-\text{LCL} = 2z_{1-0.05/2}\sqrt{2}\sigma/\sqrt{n} = 1.24\cdot\sigma\;. \] Using our previous estimate of \(\hat{\sigma}=\) 1.65, we find an expected width of the 95%-confidence interval is 2.05 compared to 2.89 for the previous experiment with 10 mice per vendor, a decrease in length by \(\sqrt{2}=1.41\) due to doubling the sample size. This is a far cry from our desired length of one, and it might be doubtful if this precision is useful in practice.
3.4 Sample size and power
A more common approach for determining the required sample size is via a hypothesis testing framework. This approach allows us to also consider acceptable false positive and false negative probabilities for our experiment. For any hypothesis test, we can always calculate each of the following five parameters from the other four:
- The sample size.
- The minimal effect size we want to reliably detect: the smaller the minimal effect size, the more samples are required to distinguish it from a zero effect. It is determined by subject-matter considerations and both raw and standardized effect sizes can be used.
- The variance: the larger the variance of the responses, the more samples we need to average out random fluctuations and achieve the necessary precision. Reducing the variance using the measures discussed above always helps, and blocking in particular is a powerful design option if available.
- The significance level \(\alpha\) of getting a false positive: the more stringent this level, the more samples we need to reliably detect a given effect. In practice, values of 5% or 1% are common.
- The power \(1-\beta\): this probability is higher the more stringent our \(\alpha\) is set (for a fixed difference) and larger effects will lead to fewer false negatives for the same \(\alpha\) level. In practice, the desired power is often about 80%; higher power of 90% might require prohibitively large sample sizes.
3.4.1 Power analysis for known variance
We start developing the main ideas for determining a required sample size in a simplified scenario, where we know the variance exactly. Then, the standard error of \(\hat{\Delta}\) is also known exactly, and the test statistic \(\hat{\Delta}/\text{se}(\hat{\Delta})\) has a standard normal distribution under the null hypothesis \(H_0: \Delta=0\). The exact same calculations can also be used with a variance estimate, provided the sample size is not too small and the \(t\)-distribution of the test statistic is well approximated by the normal distribution.
In the following, we assume that we decided on the false positive probability \(\alpha\), the power \(1-\beta\), and the minimal effect size \(\Delta=\delta_0\). If the true difference is smaller than \(\delta_0\), we might still detect it, but detection becomes less and less likely the smaller the difference gets. If the difference is greater, our chance of detection increases.
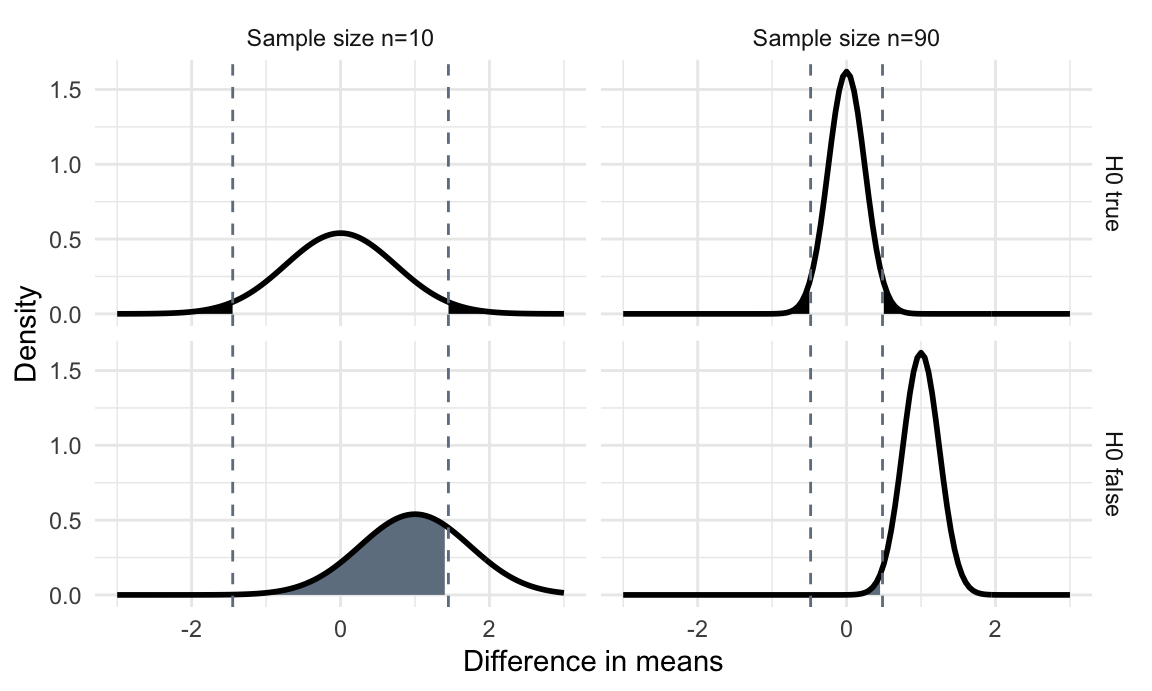
Figure 3.1: Distributions of difference in means if null hypothesis is true and difference between means is zero (top) and when alternative hypothesis is true and difference is one (bottom) for 10 (left) and 90 (right) samples. The dashed lines are the critical values for the test statistic. Shaded black region: false positives (\(\alpha\)). Shaded grey region: false negatives \(\beta\).
If \(H_0: \Delta=0\) is true, then \(\hat{\Delta}\sim N(0,2\sigma^2/n)\) has a normal distribution with mean zero and variance \(2\sigma^2/n\). We reject the null hypothesis if \(\hat{\Delta}\leq z_{\alpha/2}\cdot \sqrt{2}\sigma/\sqrt{n}\) or \(\hat{\Delta}\geq z_{1-\alpha/2}\cdot \sqrt{2}\sigma/\sqrt{n}\). These two critical values are shown as dashed vertical lines in Figure 3.1 (top) for sample sizes \(n=\) 10 (left) and \(n=\) 90 (right). As expected, the critical values move closer to zero for increasing sample size.
If \(H_0\) is not true and \(\Delta=\delta_0\), then \(\hat{\Delta}\sim N(\delta_0,2\sigma^2/n)\) has a normal distribution with mean \(\delta_0\) and variance \(2\sigma^2/n\). This distribution is shown in the bottom row of Figure 3.1 for the two sample sizes and a true difference of \(\Delta=\delta_0=\) 1; it also gets narrower with increasing sample size \(n\).
Our goal is to find \(n\) such that the probability of a false negative stays below a prescribed value \(\beta\). A false negative happens if \(H_0\) is not true, so \(\Delta=\delta_0\), yet the estimator \(\hat{\Delta}\) falls outside the rejection region. The probability of this event is \[ \mathbb{P}\left( |\hat{\Delta}|\leq z_{1-\alpha/2}\cdot\frac{\sqrt{2}\cdot\sigma}{\sqrt{n}}; \Delta=\delta_0 \right) = \beta\;, \] which yields the fundamental equality \[\begin{equation} z_{1-\alpha/2}\cdot \sqrt{2}\sigma / \sqrt{n} = z_{\beta}\cdot \sqrt{2}\sigma / \sqrt{n}+\delta_0\;. \tag{3.1} \end{equation}\] We can see this in Figure 3.1: for a given \(\alpha=5\%\), the dashed lines denote the rejection region, and the black shaded area has probability 5%. Under \(H_1: \Delta=\delta_0\), we get the distributions in the bottom row, where all values below the dashed lines are false negatives, and the probability \(\beta\) corresponds ot the grey shaded area. Increasing \(n\) from \(n=\) 10 (left) to \(n=\) 90 (right) narrows both distributions, moves the critical values towards zero, and shrinks the false negative probability.
We find a closed formula for the sample size by ‘solving Equation (3.1) for \(n\)’: \[\begin{equation} n = \frac{2\cdot(z_{1-\alpha/2}+z_{1-\beta})^2}{(\delta_0/\sigma)^2} = \frac{2\cdot(z_{1-\alpha/2}+z_{1-\beta})^2}{d_0^2} \tag{3.2}\;, \end{equation}\] where we used the fact that \(z_{\beta}=-z_{1-\beta}\). The first formula uses the minimal raw effect size \(\delta_0\) and requires knowledge of the residual variance, whereas the second formula is based on the minimal standardized effect size \(d_0=\delta_0/\sigma\), which measures the difference between the means as a multiple of the standard deviation.
In our example, a hypothesis test with significance level \(\alpha=0.05\) and a variance of \(\sigma^2=\) 2 has power 0.11, 0.35, and 1 to detect a true difference of \(\delta_0=\) 1 based on \(n=2\), \(n=10\), and \(n=100\) mice per treatment group, respectively. We require at least 31 mice per vendor to achieve a power of \(1-\beta=0.8\).
The same ideas apply to calculating the minimal effect size that is detectable with given significance level and power for any fixed sample size. For our example, we might only have 20 mice per vendor at our disposal. For our variance of \(\sigma^2=\) 2, a significance level of \(\alpha=5\%\) and a power of \(1-\beta=80\%\), we find that for \(n=20\), the achievable minimal effect size is \(\delta_0=\) 1.25.
A small minimal standardized effect size \(d_0=\Delta/\sigma=0.2\) requires at least \(n=\) 392 mice per vendor for \(\alpha=5\%\) and \(1-\beta=80\%\). This number decreases to \(n=\) 63 and \(n=\) 25 for a medium effect \(d_0=0.5\), respectively a larger effect \(d_0=0.8\).
Portable power calculation
It is convenient to have simple approximate formulas to find a rough estimate of the required sample size for a desired comparison. Such approximate formulas were termed portable power in (Wheeler 1974) and enable quick back-of-napkin calculation during a discussion, for example.
For our two-sample problem, we consider a significance level \(\alpha=5\%\) and a reasonable power of \(1-\beta=80\%\). The numerator in Equation (3.2) is then roughly 16, leading to the portable power formula \[\begin{equation} n \approx \frac{16}{(\delta_0/\sigma)^2} = \frac{16}{d_0^2} \tag{3.3}\;. \end{equation}\]
We can translate the sample size formula for a relative effect based on the coefficient of variation \(\text{CV}=\sigma/\mu\) (Belle and Martin 1993): \[ n \approx \frac{16\cdot (\text{CV})^2}{\ln(\mu_A/\mu_B)^2}\;. \] This requires taking logarithms and is not quite so portable. A convenient further shortcut exists for a variation of 35%, typical for biological systems (Belle 2008), noting that the numerator then simplifies to \(16\cdot (0.35)^2\approx 2\).
For example, a difference in enzyme level of at least 20% of vendor A compared to vendor B and a variability for both vendors of about 30% means that \[ \frac{\mu_A}{\mu_B}=0.8 \quad\text{and}\quad \frac{\sigma_A}{\mu_A}=\frac{\sigma_B}{\mu_B} = 0.3\;. \] The necessary sample size per vendor is then \[ n \approx \frac{16\cdot (0.3)^2}{\ln(0.8)^2} \approx 29\;. \] For a higher variability of 35%, the sample size increases, and our shortcut yields \(n \approx 2/\ln(\mu_A/\mu_B)^2\approx 40\).
3.4.2 Power analysis for unknown variance
In practice, the variance \(\sigma^2\) is usually not known and the test statistic \(T\) uses an estimate \(\hat{\sigma}^2\) instead. If \(H_0\) is true and \(\Delta=0\), then \(T\) has a \(t\)-distribution with \(2n-2\) degrees of freedom, and its quantiles depend on the sample size. If \(H_0\) is false and the true difference is \(\Delta=\delta_0\), then the test statistic has a non-central \(t\)-distribution with non-centrality parameter \[ \eta = \frac{\delta_0}{2\cdot\sigma/\sqrt{n}} = \sqrt{n/2}\cdot d_0\;. \] For illustration, Figure 3.2 shows the density of the \(t\)-distribution for different number of samples and different values of the non-centrality parameter; note that the noncentral \(t\)-distribution is not symmetric, and \(t_{n,\alpha}(\eta)\not= -t_{n,1-\alpha}(\eta)\).
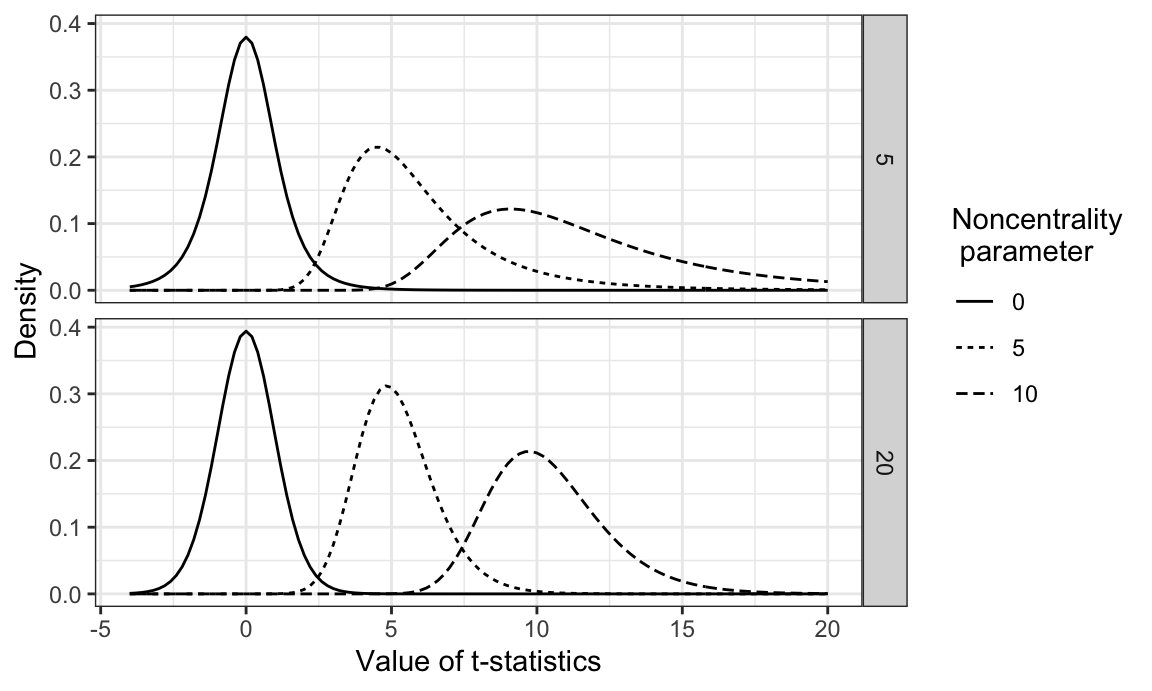
Figure 3.2: t-distribution for 5 (top) and 20 (bottom) degrees of freedom and three different noncentrality parameters (linetype).
An increase in sample size has two effects on the distribution of the test statistic \(T\): (i) it moves the critical values inwards, although this effect is only pronounced for small sample sizes; (ii) it increases the noncentrality parameter with \(\sqrt{n}\) and thereby shifts the distribution away from zero. This is in contrast to the our earlier discussion on the difference \(\hat{\Delta}\), where an increase in sample size results in a decrease in the variance.
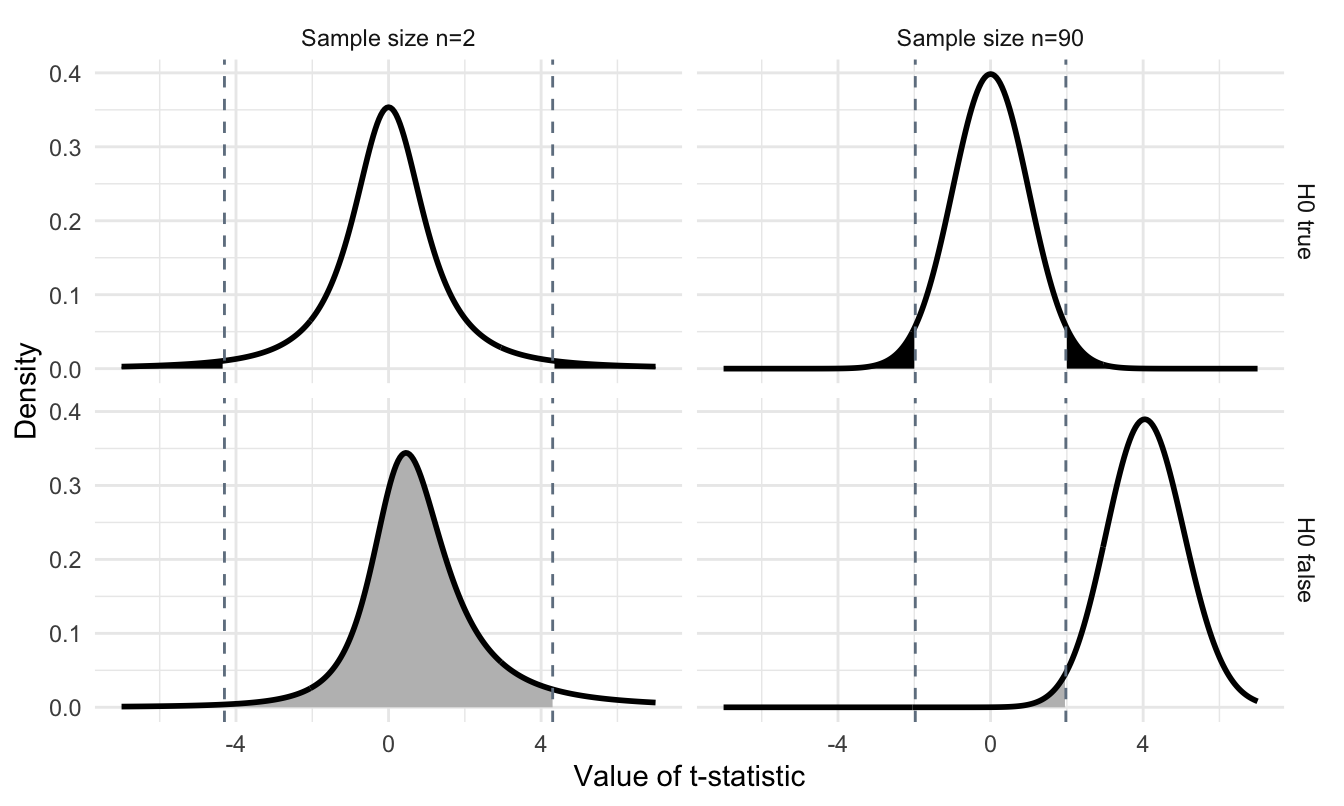
Figure 3.3: Distributions of difference in means if null hypothesis is true and true difference is zero (top) and when alternative hypothesis is true and true difference is one (bottom) for 2 (left) and 90 (right) samples. The dashed lines are the critical values for the test statistic. Shaded black region: false positives (\(\alpha\)). Shaded grey region: false negatives \(\beta\).
As an example of a simple power calculation, assume we have reason to believe that the two kits indeed give consistently different readouts. Based on a significance level of \(\alpha=5\%\), we calculate the power that we successfully detect a true difference of \(|\Delta|=\delta_0=2\), of \(\delta_0=1\), and of \(\delta_0=0.5\). Under the null hypothesis, the test statistics \(T\) has a (central) \(t\)-distribution with \(2n-2\) degrees of freedom, and we reject the hypothesis if \(|T|>t_{2n-2, 1-\alpha/2}\). If however, \(\Delta=\delta_0\) is true, then the distribution of \(T\) changes to a noncentral \(t\)-distribution with \(2n-2\) degrees of freedom and noncentrality parameters \(\eta=\delta_0 / \text{se}(\hat{\Delta})\). The power \(1-\beta\) is the probability that this \(T\) falls into the rejection region and either stays above \(t_{2n-2, 1-\alpha/2}\) or below \(t_{2n-2, \alpha/2}\).
We compute the upper end of the rejection region for \(\delta_0=2\) as 1.55, and the probability to stay below this value (and correctly reject \(H_0\)) is very high with a power of 0.87. This is because the standard error is 0.74 and thus the precision of the estimate \(\hat{\Delta}\) is large compared to the difference we attempt to detect. Decreasing this difference while keeping the significance level and the sample size fix decreases the power to 0.43 for \(\delta_0=1\) and further to 0.22 for \(\delta_0=0.5\). In other words, we can expect to detect a true difference of \(\delta_0=0.5\) in only 22% of experiments with 10 samples per vendor and it is questionable if such an experiment is worth implementing.
It is not possible to find a closed formula for the sample size calculation, because the central and noncentral \(t\)-quantiles depend on \(n\), while the noncentrality parameter depends on \(n\) and additionally alters the shape of the noncentral \(t\)-distribution. R’s built-in function power.t.test() uses an iterative approach and yields a (deceptively precise!) required sample size of \(n=\) 43.8549046 per vendor based on our previous estimate \(\hat{\sigma}^2=\) 2.73 of the variance.
Note that we replaced the unknown true variance with an estimate \(\hat{\sigma}^2\) for this calculation, and the accuracy of the resulting sample size hinges partly on the assumption that the variance estimate is reasonably close to the true variance.
We can also implement the power analysis by hand. The code below calculates the power of a \(t\)-test given the minimal difference delta, the significance level alpha, the sample size n, and the standard deviation s. It first calculates the degrees of freedom for the given sample size. Then, the lower and upper critical values for the \(t\)-statistic under the null hypothesis are computed. Next, the noncentrality parameter \(\eta=\) ncp is used to determine the probability of correctly rejecting \(H_0\) if indeed \(|\Delta|=\delta_0\); this is precisely the power.
# delta: difference under HA
# alpha: significance level (false positive rate)
# n: sample size
# s: estimate of residual standard deviation
# return: power to reject
getPowerT = function(delta0, alpha, n, s) {
# degrees of freedom
df = 2*n-2
# lower alpha/2 quantile if H0 is true -> rejection region
quant.H0.low = qt(p=alpha/2, df=df)
quant.H0.high = qt(p=1-alpha/2, df=df)
# noncentrality parameter
ncp = abs(delta0) / (sqrt(2)*s/sqrt(n))
# probability to reject low value if H0 false
prob.reject.H0.low = pt(q=quant.H0.low, df=df, ncp=ncp)
# probability to reject high value if H0 false
prob.reject.H0.high = 1 - pt(q=quant.H0.high, df=df, ncp=ncp)
# probability to reject value if H0 false = 1-beta = power
prob.reject.H0 = prob.reject.H0.low + prob.reject.H0.high
return(prob.reject.H0)
}We can use this function by starting from a reasonably low \(n\) (for example, \(n=5\)), calculating the power, and increasing the sample size until the desired power is reached. For our example, this also yields a sample size of \(n=\) 0 mice per vendor.
References
Belle, Gerald van. 2008. Statistical Rules of Thumb: Second Edition. https://doi.org/10.1002/9780470377963.
Belle, Gerald van, and Donald C Martin. 1993. “Sample size as a function of coefficient of variation and ratio.” American Statistician 47 (3): 165–67.
Hurlbert, Stuart. 1984. “Pseudoreplication and the Design of Ecological Field Experiments.” Ecological Monographs 54 (2). Ecological Society of America: 187–211. https://doi.org/10.2307/1942661.
Wheeler, Robert E. 1974. “Portable Power.” Technometrics 16 (2): 193–201. https://doi.org/10.1080/00401706.1974.10489174.